Learning to enhance and share collections with IIIF
Guest post by Alison Harvey, Archivist at Cardiff University
In June 2020, like many in the heritage sector, I was a collection specialist without a collection. The COVID-19 pandemic had closed our library buildings indefinitely, and with them, eliminated access to the books and archives that are the daily tools of our profession. As I worked at a laptop in my bedroom, an unknown future stretching ahead, my role felt as precarious as my makeshift desk.
I scoured Twitter for news of digital training and development opportunities. A previously unimaginable number of free courses, conferences and workshops were on offer, as heritage organisations scrambled to reschedule and redesign planned in-person events. Here, I found some light in dark days, as I enrolled myself in more training in a few months than I had been able to physically attend in a 15-year career in archives.
I signed up for anything I had ever been curious about, with the aim to explore as many remote alternatives to collection access, engagement, and enrichment as possible. I learned about Wikipedia, Wikidata, transcription platforms such as Transkribus and From The Page, digital preservation, web archiving, linked data, Open Refine, SQL, and Git. I used machine learning to train a model to read handwriting from our largest archive, and even learned to code with Python. The most useful training I attended, by far, was the IIIF (International Image Interoperability Framework) workshop.
I had been aware of some of the benefits of IIIF for some time. For instance, that it enables images from different digital repositories to be juxtaposed and compared via web interfaces, through an underlying shared infrastructure. The technical details and the terminology, however, were a mystery to me. Something about APIs? I wanted to find out more.
The workshop immediately followed the week-long IIIF annual conference, which would have been held in Boston, MA, but due to the pandemic, was now free to access online. Sessions were aimed at everyone from complete beginners to seasoned implementers, and all were recorded and made publicly available on the IIIF YouTube channel. During the conference, I would learn far more about the potential for IIIF beyond just digital reunification.

- Deep zoom with large images: In this striking example from Stanford University, an 11 x 17 feet map has been made accessible using IIIF. This huge composite file of 158 digital images measuring 34,000 x 22,000 pixels doesn’t require download. IIIF fragments files into smaller tiled units, which means that as a user zooms in to examine a section, that section alone is rendered. As a result, images load rapidly and smoothly to allow deep zoom navigation, all within the browser.
- Comparing images: The Library of Congress has used multispectral imaging to reveal lines in a letter by Alexander Hamilton that had been written over in another ink. The different inks respond to different light wavelengths, which allow the two inks to be illuminated separately, fading out the overwritten sections to reveal the undertext. The two versions can then be displayed side by side.
- Reunifying images: The Fragmentarium project reunifies manuscripts which have been broken up and sold to disparate owners, and reunifies them using IIIF as single digital objects.
- Georeferencing: The National Library of Scotland has compared historical and modern maps with overlays using Georeferencer.
- Search within: The National Library of Wales has used IIIF’s annotation capability to allow text, cartoons, graphs, illustrations, maps and photographs to be identified within 15 million newspaper articles.
- Annotation: The ability to annotate images also allows for their enrichment through crowdsourced metadata. The Omeka-hosted Indigenous Digital Archive allows users to tag government records from the National Archives of America, extracting information about schools, tribes, people, places, and themes.
- Storytelling: Cogapp and Digirati work with museums to tell digital stories about objects — a viewer can control their journey as they examine an item, zooming into details to view relevant annotations.
Following five intense days of discovering what IIIF can do, I embarked on another five intense days of learning exactly how to do it. The IIIF workshop was open to 25 participants, who were assigned to five small tutor groups, each headed by a IIIF expert. This small-group approach facilitated communication and peer support via a dedicated Slack channel, allowing us to stay in touch despite being based in different countries. Together, we worked through each day’s exercises, and towards our end goal of creating our own IIIF project to demonstrate on a video call at the end of the week.
Each day, we attended presentations and practical demonstrations. As participants on the June course were based in the USA and Europe, video calls were scheduled in the late afternoon for those in the UK, and recorded for anyone unable to attend live. This allowed me to spend most of each day working through the material from the previous session at my own pace, and to complete the practical tasks that were set.
As someone who prefers to learn by doing, I found this hands-on approach very engaging. We were shown how to use GitHub pages to host our work, and each day, we built on what we had made the day before. Our learning progressed intuitively, and it was satisfying to see our projects develop over time.
We began by getting started with image servers, and I learned with interest that it was possible to serve IIIF images using a tool I was already familiar with — the Internet Archive. In the early weeks of lockdown, I had worked to migrate content from Cardiff University’s end-of-life digital platform. The emergency response to COVID-19 had disrupted our procurement of a new system, and I needed to swiftly find a home for our digital resources at a time when they were more in demand than ever.
The Internet Archive enables anyone to upload and freely host digital content, allowing it to be shared with the world via a range of customisable licences. OCR is automatically applied to any image containing text, allowing researchers to search within items as well as across them, and objects can be downloaded in a range of accessible formats. Metadata is visible to Google — a distinct advantage over hosting in a siloed institutional repository.
I was already a convert. Now, I learned that the Internet Archive could also serve IIIF compliant images, accessed by forming a URL from the filename. It lacks sophistication but allows anyone lacking an expensive institutional infrastructure to explore the potential of IIIF. I began by uploading two versions of an illustration used in Moxon’s 1857 edition of Tennyson’s poems: Dante Gabriel Rossetti’s original sketched design for ‘The Palace of Art’, and the final engraving by the Dalziel brothers.

These are two images I routinely use for teaching with students. The engraving varies from the design in several places — an excellent example of the problematic relationship between Victorian wood engravers and artists. IIIF allows the images to be compared with far greater effectiveness than I had ever achieved with the physical items. I used a tool called Compariscope to digitally layer the two images. Each can be gradually exposed to allow the differences to be directly compared. The V&A has recently developed a similar tool for their Raphael cartoons, delivering a remarkable viewing experience to compare their underdrawings, paint layers, and surface textures.
We then looked at combining multiple images into a single digital object, and understanding some of the Presentation API terminology. We learnt that images are annotated onto a ‘canvas’, canvases are arranged into a ‘sequence’ to represent the correct viewing order and finally published as a ‘manifest’. We were able to take our images hosted in the Internet Archive, and use them to create IIIF manifests with the Bodleian manifest editor.
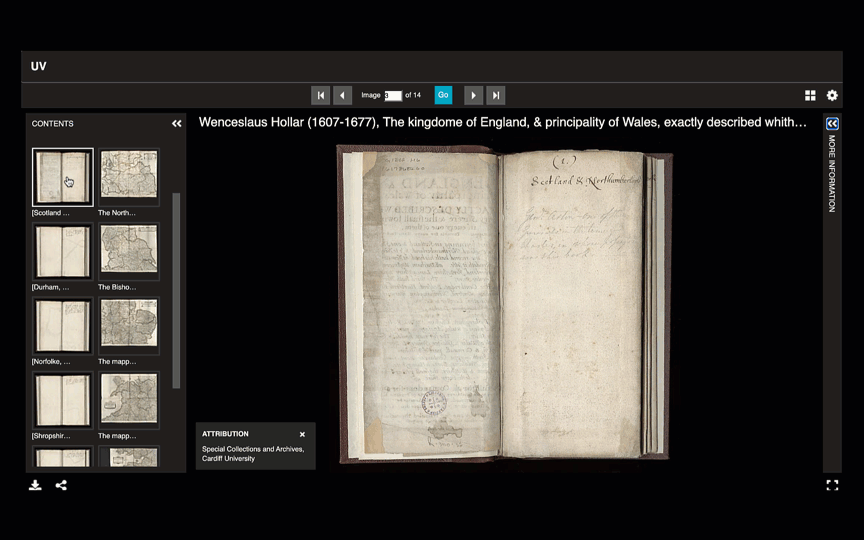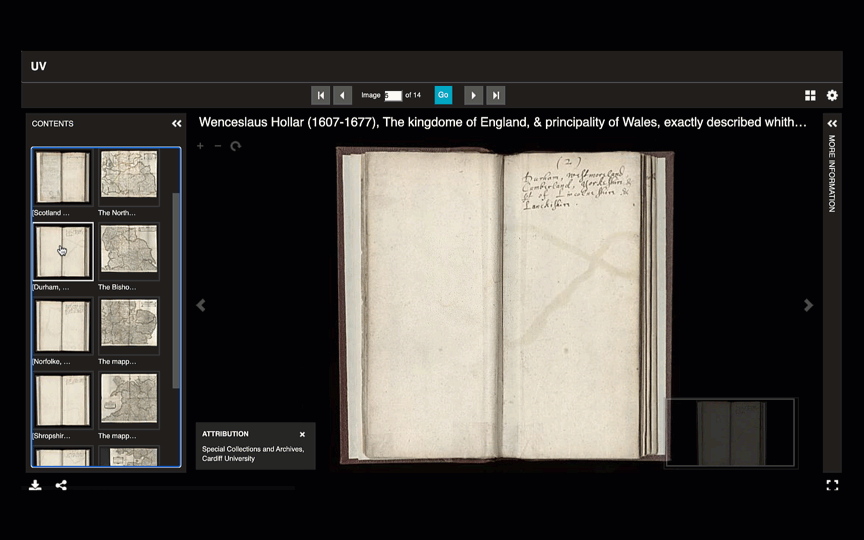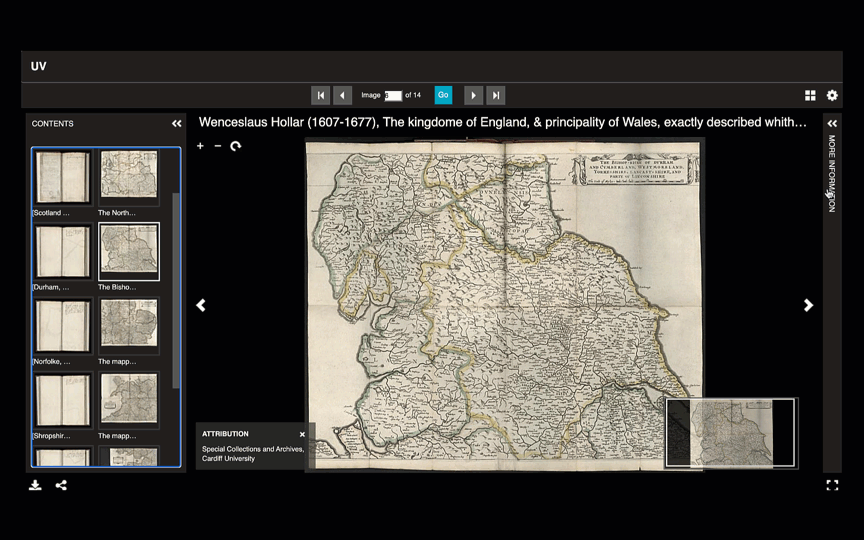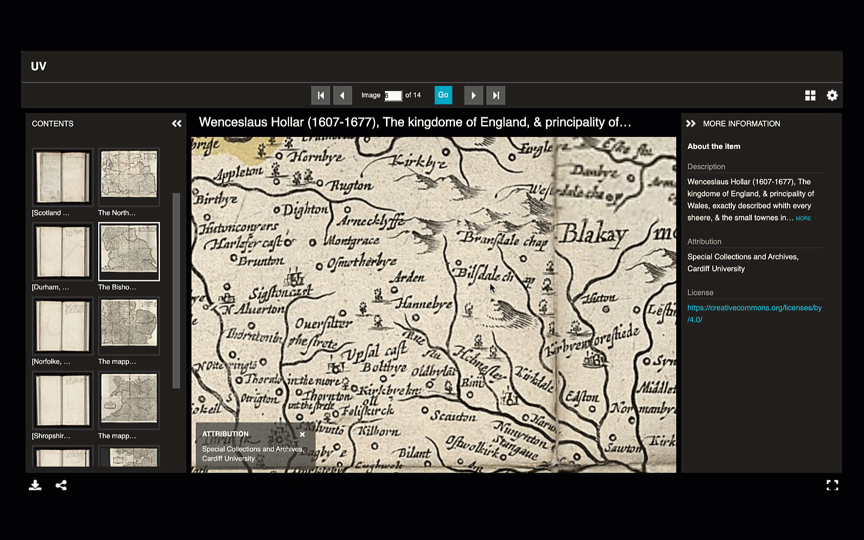
Finally, we looked at annotating IIIF manifests, and how to set up an annotation server. The real power of IIIF images is in their capacity to be enhanced with transcribed text, highlighted details, commentary, and analysis of their content. I used the Storiiies app to add annotations to the Dalziel engraving. This tool allows collection specialists to replicate the pedagogical experience of talking students through details of an object.

The University of St Andrews has recently developed a similar storytelling tool, exhibit.so, which I will be using to support teaching and assessment this academic year.
The examples shared here are all hosted on a single GitHub page. I used it in my final presentation to demonstrate the different skills I had developed, and continue to refer to it when advocating for IIIF and its capabilities.
There have been long-term benefits to the training for Special Collections and Archives. I was so convinced by the potential offered by the Internet Archive as a hosting service, I proposed migrating all our legacy content, not just that which was in immediate need of a new home. To achieve this, I used my new skills with Python to scale up from individual to bulk file ingest, and at the same time ensured that all our digital metadata was standardised to Dublin Core.
Now that we have access to consistent and interoperable content and metadata, we have been able to make agile responses to new opportunities, such as sharing our metadata with the Global Digitised Data Network project Open Texts. Direct control over Internet Archive ingest allows us to respond quickly to national media interest in our collections, as we are able to make new digital content live within the hour to support a press release.
We have also been able to swiftly respond to a recent call by JSTOR Open Community Collections, who are currently offering institutions free hosting for a pilot period. With minimal input on our part, our images and metadata were harvested directly from the Internet Archive within a day of signing a Memorandum of Understanding.
Between the Internet Archive and JSTOR, our digital content has never been more accessible or as heavily used. JSTOR’s analytics dashboard allows us to evidence demand, and its IIIF viewer tangibly demonstrates its advantages. We are now using both to leverage support to invest in a IIIF-compliant, institutional digital asset management system.
I completed the training fully convinced of the potential of IIIF, and continue to advocate for its adoption both within my own institution and in the wider research community. Previous course materials, including recordings, are freely available online for anyone wishing to find out more, and fee-paid workshops with the benefit of guided support and expertise are regularly advertised via Twitter. I would strongly recommend the training to anyone keen to ignite and support innovative and engaging research, teaching, and assessment in unpredictable times
